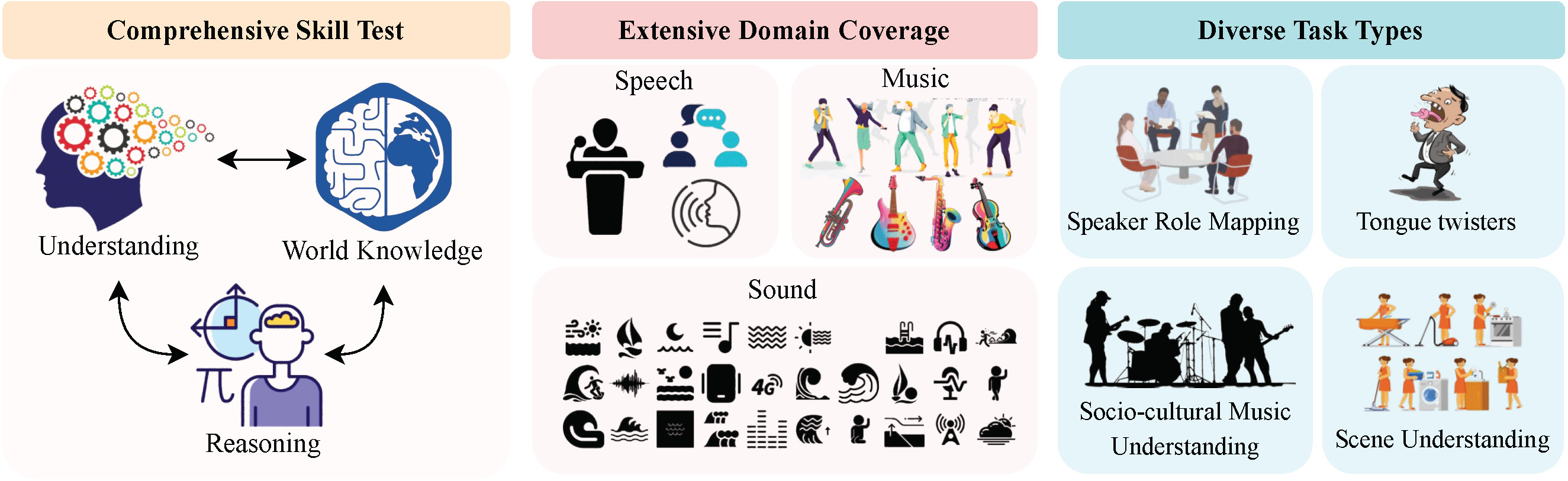
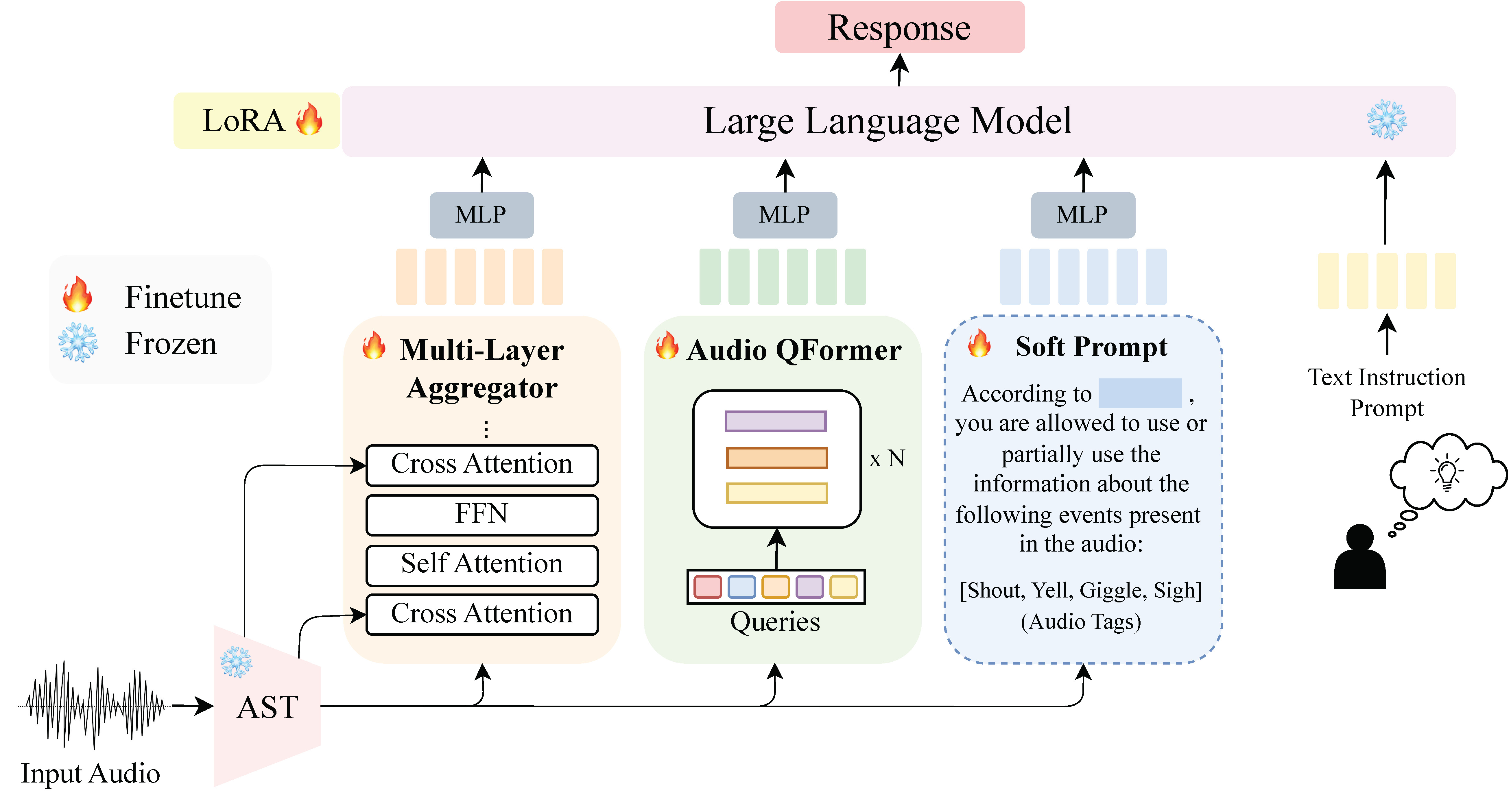
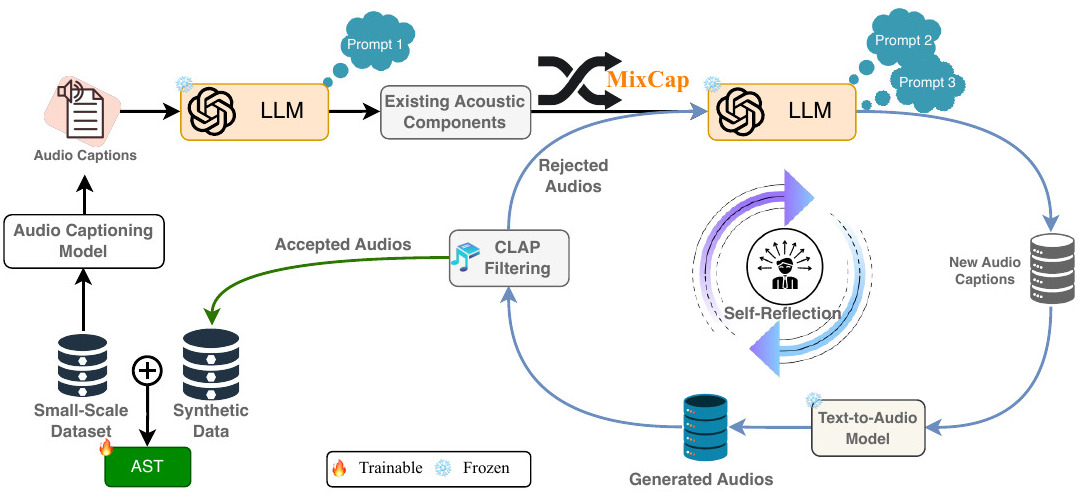
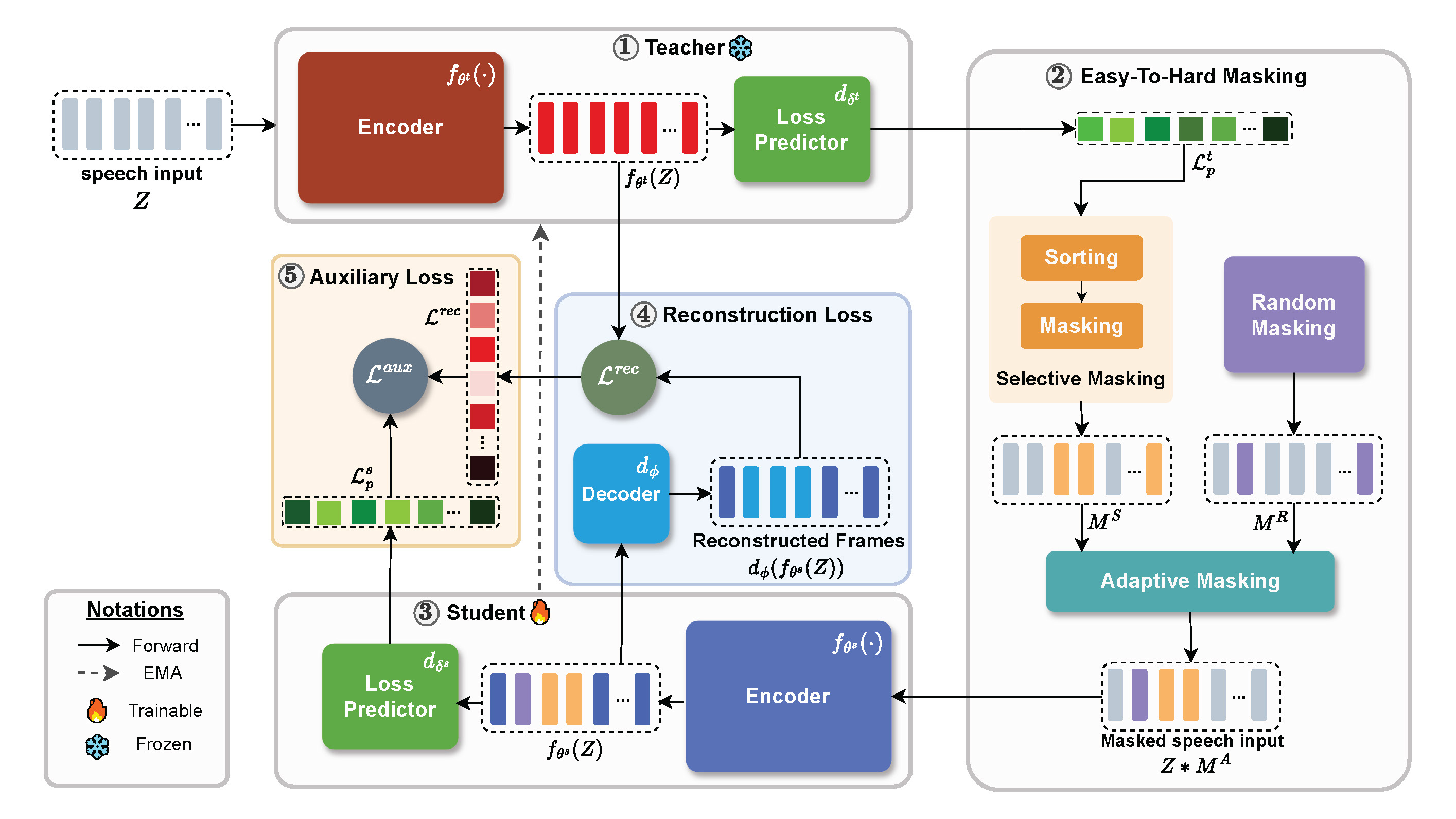
Hi, I'm Sonal Kumar
I am a Ph.D. student in Computer Science at the University of Maryland, College Park, working under Prof. Dinesh Manocha and Prof. Ramani Duraiswami. As part of the Gamma Lab and PIRL Lab, my research is centered on audio-language models, multimodal learning, and advanced reasoning in speech and audio processing.
Previously, I was a Software Engineer II at Cisco Systems, and a Research Scientist Intern at Adobe, where I focused on audio generative models. I graduated with a B.Tech in Computer Science from Christ University in 2021, where I served as President of Neuron, the university's first AI club.