GAMA: A Large Audio-Language Model with Advanced Audio Understanding and Complex Reasoning Abilities
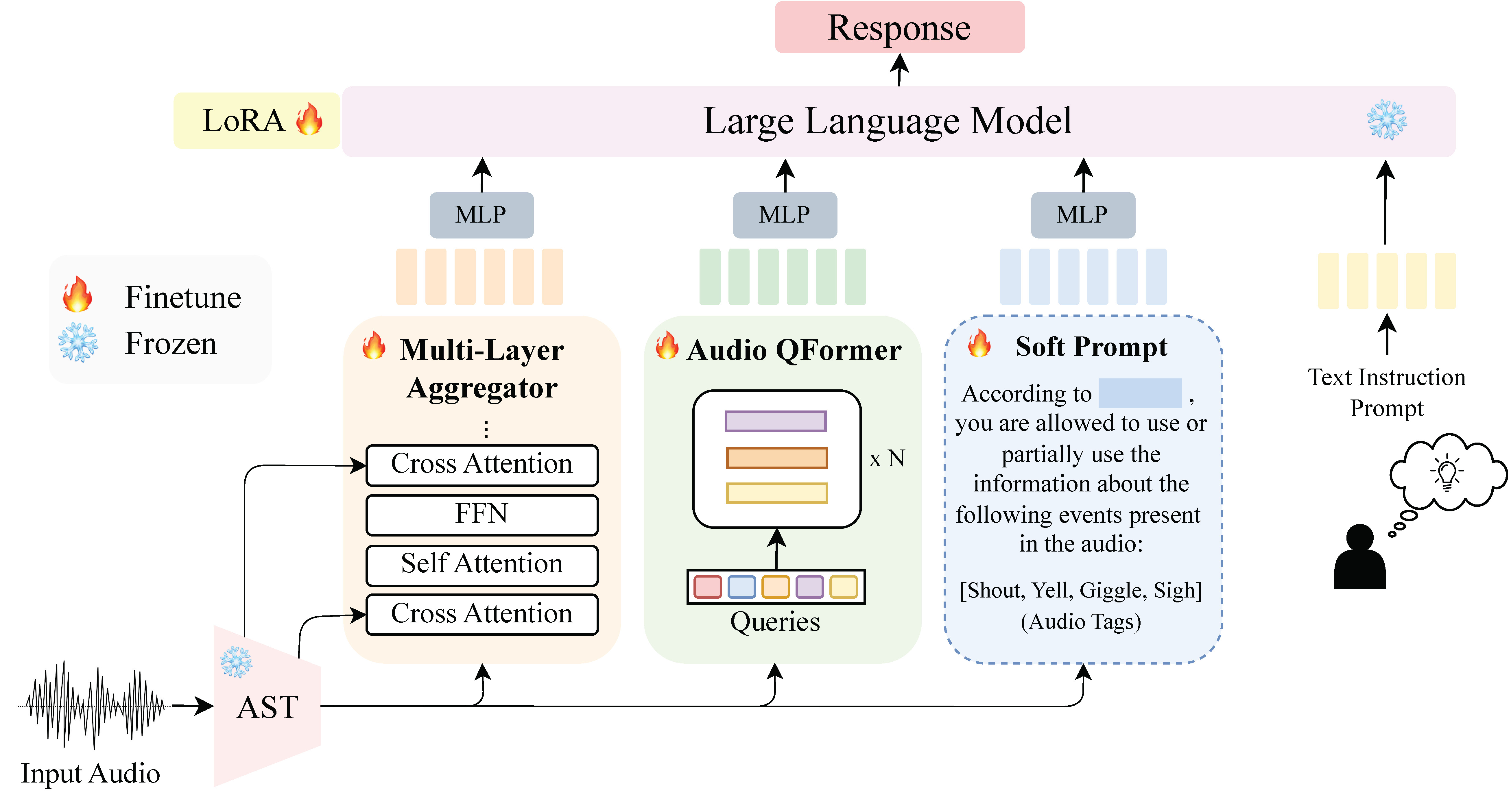
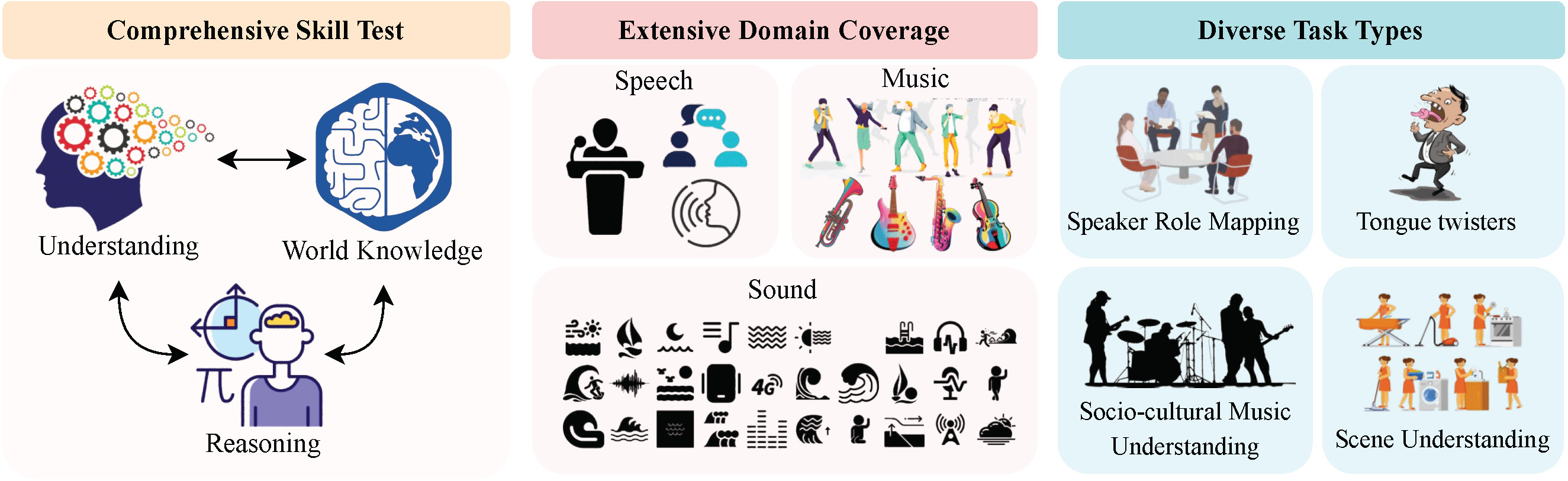
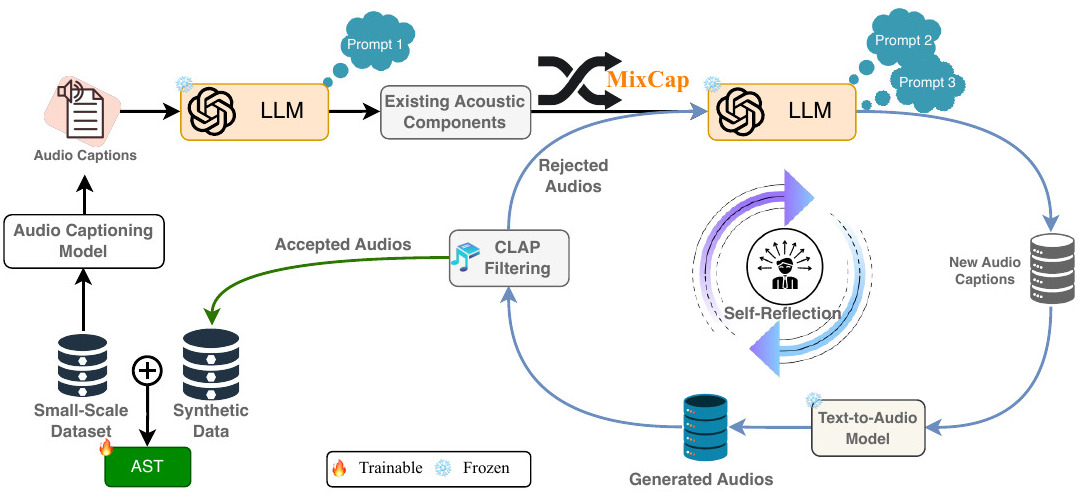
We propose GAMA, a novel Large Audio-Language Model (LALM) that is capable of responding accurately to complex questions about an input audio. GAMA benefits from a mixture of encoders and synthetic data generated using a novel data generation pipeline we propose. GAMA currently stands as the state-of-the-art LALM on various audio understanding, reasoning, and hallucination benchmarks.